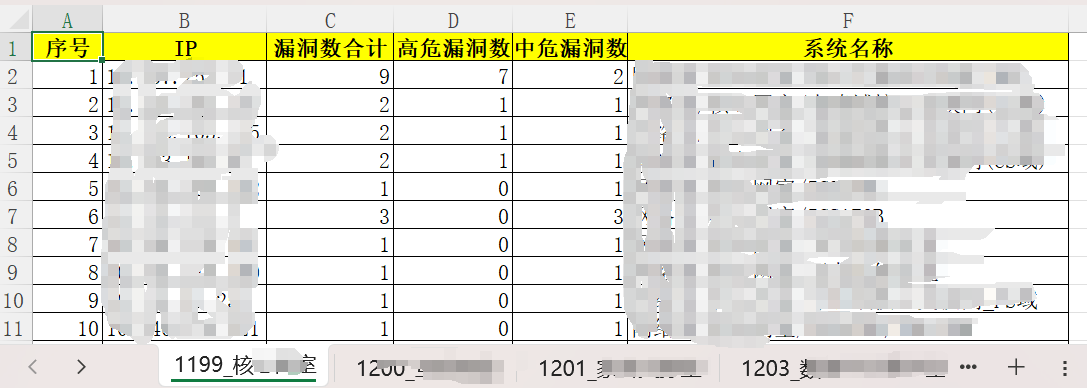
编写该脚本目的使得日常重复工作自动化,主要功能为从漏扫报告和资产表中提取IP、漏洞数、部门、系统名称等,以部门名称为sheet表名生成excel表
# -*- coding: utf-8 -*-
import json,os,re
import pandas as pd
from datetime import datetime
from openpyxl import load_workbook
from openpyxl.styles import Border, Side, PatternFill
# 用于从Excel表格中读取数据
def read_excel_data(file_path, sheet_name):
try:
# 使用pandas读取Excel文件
df = pd.read_excel(file_path, sheet_name=sheet_name, engine='openpyxl')
return df
except FileNotFoundError:
print(f"错误:文件 {file_path} 未找到。")
return None
except Exception as e:
print(f"读取Excel文件时发生错误:{e}")
return None
# 用于搜索当前IP并返回对应的系统名称
def search_current_ip(df, ip_column, system_name_column,current_ip):
try:
# 在DataFrame中搜索当前IP
matched_row = df[df[ip_column] == current_ip]
# 如果找到匹配项,则返回系统名称;否则返回None
if not matched_row.empty:
return matched_row[system_name_column].iloc[0]
else:
return None
except Exception as e:
print(f"搜索IP时发生错误:{e}")
return None
# 获取html中的json数据
def search_html_json(html_path):
with open(html_path, "r", encoding="utf-8") as file:
html_content = file.read()
# 获取html文件的json数据,默认贪婪模式
data = re.search(r'{"host_list".+\.html"}]',html_content).group()
# print(type(data))
data = data + "}"
# 将str解析为json数据
json_data = json.loads(data)
return json_data
def dir_name(root_path):
# 获取当前文件夹下的所有文件和文件夹名称
current_directory = root_path
files_and_dirs = os.listdir(current_directory)
folders = [f for f in files_and_dirs if os.path.isdir(os.path.join(current_directory, f))]
return folders
# with open("test.html", "w", encoding="utf-8") as file2:
# file2.write(data)
# 设置表格全边框、列名填充颜色
def excl_style(final_name,total_name):
wb = load_workbook(final_name)
for Fname in total_name:
ws = wb[Fname]
# 设置全边框
border = Border(left=Side(style='thin'),
right=Side(style='thin'),
top=Side(style='thin'),
bottom=Side(style='thin'))
for row in ws.iter_rows(min_row=1, max_col=ws.max_column, max_row=ws.max_row):
for cell in row:
cell.border = border
# 设置第一行(列名)为黄色背景
fill = PatternFill(start_color="FFFF00", end_color="FFFF00", fill_type="solid")
for cell in ws[1]:
cell.fill = fill
# 保存最终的文件
wb.save(final_name)
# 运行主函数
if __name__ == "__main__":
# 指定要读取的资产表Excel文件的路径和表单名
file_path = './test.xlsx' # 请替换为你的Excel文件路径
sheet_name = 'Sheet1' # 请替换为你的表单名
# 读取Excel数据
df = read_excel_data(file_path, sheet_name)
# 如果数据读取成功
if df is not None:
# 定义IP列和系统名称列的列名(请根据你的Excel表格进行替换)
ip_column = 'ip地址'
system_name_column = '资产名称'
#设置扫描报告路径
root_path = "./初扫/"
file_name = dir_name(root_path)
# 指定Excel文件的输出路径
output_file = str(datetime.now().month) + '月漏洞统计.xlsx'
# 使用ExcelWriter上下文管理器,可将多个sheet工作表写入同一excl文件
with pd.ExcelWriter(output_file, engine='openpyxl') as writer:
for Fname in file_name:
# 设置每个科室的具体报告路径
html = root_path + Fname + '/' + 'index.html'
#获取报告中的IP、高、中危漏洞数
json_data = search_html_json(html)
extracted_data = []
i = 0
# 提取列表中 target_ip、vuln_high、vuln_middle
for host in json_data["host_list"]:
if (host["vuln_high"]+host["vuln_middle"]) > 0:
i += 1
vuln_total = host["vuln_high"] + host["vuln_middle"]
try:
extracted_data.append({
"序号": i,
"IP": host["target_ip"],
"漏洞数合计": vuln_total,
"高危漏洞数": host["vuln_high"],
"中危漏洞数": host["vuln_middle"],
"系统名称": search_current_ip(df, ip_column, system_name_column,host["target_ip"]).replace("xxx有限公司/",'')
})
except AttributeError:
extracted_data.append({
"序号": i,
"IP": host["target_ip"],
"漏洞数合计": vuln_total,
"高危漏洞数": host["vuln_high"],
"中危漏洞数": host["vuln_middle"],
"系统名称": "IP在资产表中未查到"
})
if len(extracted_data) > 0:
# 将数据列表转换为DataFrame
DataFrame = pd.DataFrame(extracted_data)
# 使用pandas将DataFrame写入Excel文件
DataFrame.to_excel(writer, sheet_name=Fname, index=False)
#设置表格样式
excl_style(output_file,file_name)
最后效果为:生成一个excl表格,每个部门科室有单独sheet工作表,每个sheet表中存在序号、IP、高中危漏洞以及总数、系统名称。