
目录导航
requirements.txt
如今,许多 Web 应用程序受到 Cloudfare、Akamai 等服务的保护……隐藏其真实 IP 地址,这可能是我们执行渗透测试或尝试利用漏洞时的障碍。
在这篇文章中,我想分享一种技术,可以在许多情况下帮助我们找到真实的 IP 地址。
这个过程有两个部分:
- 确定可以托管服务器的 ipv4 范围。
- 使用 http 请求对范围进行暴力破解。
第 1 部分:确定与组织相关的 ipv4 范围
让我们开始假设我们要查找下一个网站的真实 ip:
https://examplecorp.com
任何 Web 应用程序都位于发布到 Internet 的服务器中,其 IP 地址属于一个 ip 范围,并且该范围归组织所有。我们要做的第一件事是去一个在线的 ipv4 数据库,比如Ipv4info或WhoisXMLAPI并寻找“Example Corp”,这样我们就会找到一个或多个属于该组织的 IP 地址范围进行攻击。
另一种方法是在其他服务中查找 IP 地址,例如子域、邮件服务器等……想象一下,您找到了一个子域,例如:
webmail.examplecorp.com
这个子域解析一个 ip 地址,这个 ip 可以托管在 AWS、Azure 等服务中……好吧,我们可以假设目标基础设施的一部分可以托管在这个提供商中,我们可以在Ipv4info或WhoisXMLAPI 中找到提供商 ip子域IP的范围。
如您所见,这部分只是正确思考如何找到网站服务器可能位于的可能的 ipv4 范围。
第 2 部分:使用 http 请求对 ipv4 范围进行暴力破解
此时,我们怀疑有一些 ipv4 范围可以托管网站服务器,我们基本上需要使用网站主机名发送 http 请求,并检查是否有任何范围的 ipv4 地址响应网站。
考虑到 0.0.0.0/24 范围有 256 个 IP 地址,或者 0.0.0.0/16 范围有 65,536 个,您可以一一尝试。

借助工具加速爆破
为了提供帮助,我开发了一个自动化这部分的 python 工具:
https://github.com/elefr3n/real_ip_discover
我们需要为脚本设置接下来的三个位置参数:
-hostname (例如.ddosi.org )
-target_list 范围或 ips 列表 (例如: 0.0.0.0/24,1.1.1.1/16,2.2.2.2)
-match (例如:<title>?雨苁ℒ?暗网|黑客|极客|渗透测试|专注信息安全|数据泄露|隐私保护</title>)
我们还可以将可选参数设置为超时、线程、uri 等……
该工具向我们提供的范围和 ip 中的每个 ip 地址发送 http 和 https 请求,并在标头中包含网站主机名,检查是否有任何 ip 地址响应我们设置的匹配项。
现在,我想展示该工具的示例用法,显然出于法律原因,该网站不受任何服务保护以隐藏其 IP 地址。
假设网站 cisco.com 在 Cloudflare 后面,并且怀疑它可以托管在 72.163.4.0/24 范围内,我们运行该工具,如下图所示:
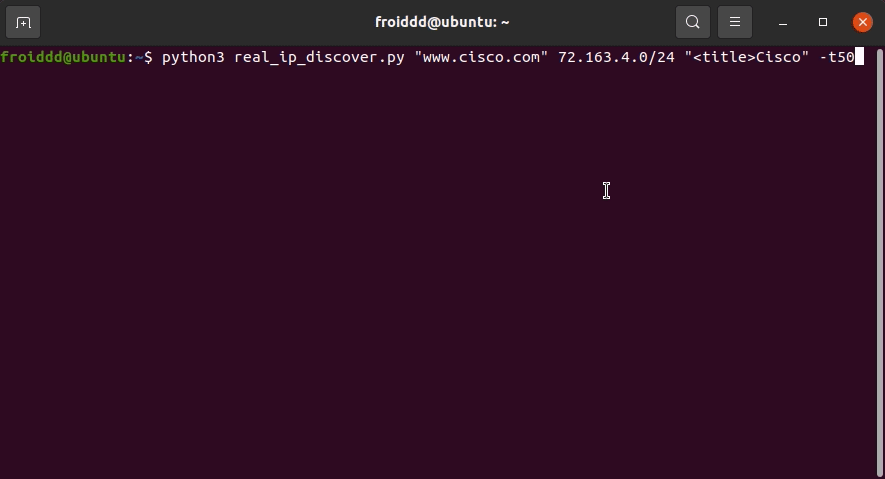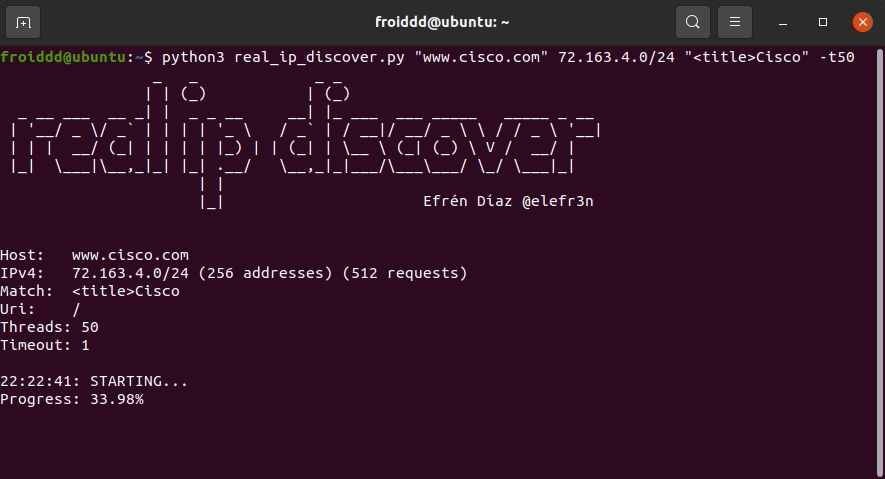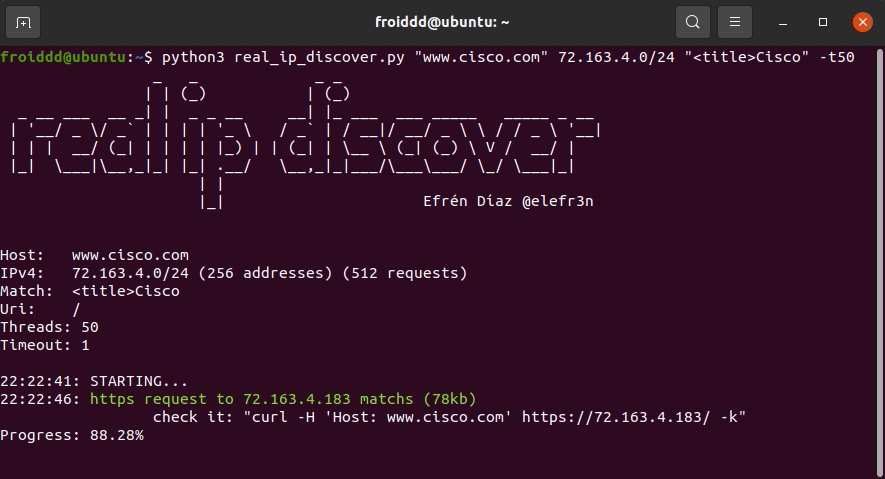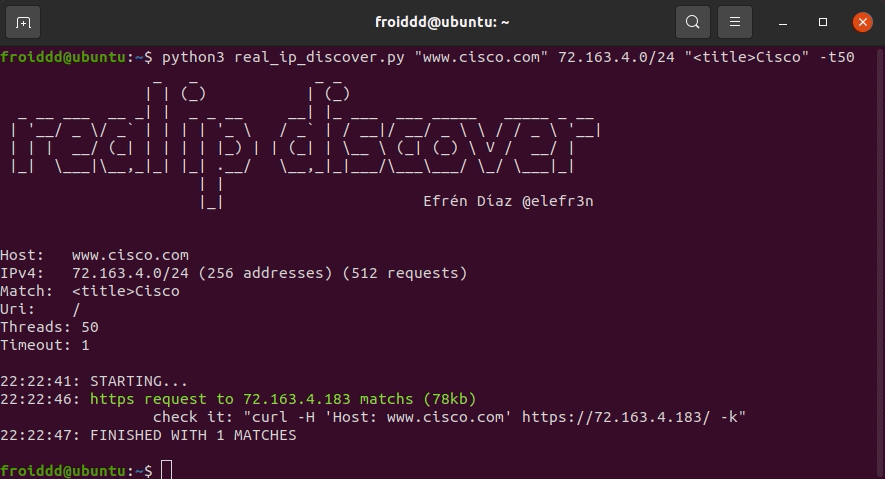
该工具检测到 ip 72.163.4.183 在收到带有www.cisco.com主机名的 http 请求时响应我们设置的“<title>Cisco”匹配项,此时我们就有了真实的网站 ip。
完成这篇文章,我想评论一下,保护我们的 Web 服务器真的很容易,就像在防火墙、iptables 或任何其他可用的安全配置中设置一些规则一样简单,您应该只允许从我们所在的服务 ip 范围接收连接使用。例如,如果您使用 Cloudflare,他们会提供一个链接,您可以在其中获取所有 ipv4 范围:
就是这样,我真的希望这篇文章对大家有用.
real_ip_discover介绍
描述
此工具可帮助您找到受Cloudflare、Akamai 和其他 WAF/CDN 服务等服务保护的服务器真实 IP 地址…
real_ip_discover 怎么运作?
提供主机名(例如:site.com)、网站 html 匹配(例如:“welmcome to site.com”)和 ipv4 地址或范围列表,此工具将向所有 ipv4 地址发送 http/s 请求,检查是否有任何他们以比赛回应。
我怎样才能获得可能的 ipv4 范围?
有很多方法可以找到可以托管真实服务器 IP 地址的可能的 ipv4 范围,这里我公开一些:
- 在 ipv4info.com 等在线服务中搜索目标公司 ipv4 范围/地址
- Shodan、Censys…
- 获取子域中公开的 ipv4 地址范围
- 获取电子邮件原始数据中公开的 ipv4 地址范围
- 尝试在 dns 历史记录中获取更多 ipv4 地址
real_ip_discover工具下载地址
①GitHub:
github.com/elefr3n/real_ip_discover.zip
②云中转:
yunzhongzhuan.com/#sharefile=xtEjLClb_…
解压密码: www.ddosi.org
③直接复制如下代码重命名为.py即可使用,别忘了requirements
#!/usr/bin/python3
import logging
import os
import sys
from argparse import SUPPRESS, ArgumentParser
import requests
import urllib3
from netaddr import *
import _thread
import itertools
import math
try:
urllib3.disable_warnings(urllib3.exceptions.InsecureRequestWarning)
except ImportError as ie:
print(ie)
LOGGING_FORMAT = "%(asctime)s: %(message)s"
PROTOCOLS = ("http", "https")
range_length = 0
total_requests = 0
sent_requests = 0
matches = 0
def print_banner(args):
global range_length, total_requests
print(" _ _ _ _ ")
print(" | | (_) | (_) ")
print(" _ __ ___ __ _| | _ _ __ __| |_ ___ ___ _____ _____ _ __ ")
print(" | '__/ _ \/ _` | | | | '_ \ / _` | / __|/ __/ _ \ \ / / _ \ '__|")
print(" | | | __/ (_| | | | | |_) | | (_| | \__ \ (_| (_) \ V / __/ | ")
print(" |_| \___|\__,_|_| |_| .__/ \__,_|_|___/\___\___/ \_/ \___|_| ")
print(" | | ")
print(" |_| Efrén Díaz @elefr3n \n\n")
print(f"Host: \t{args.hostname}")
print(f"IPv4: \t{args.target_list} ({range_length} addresses) ({total_requests} requests)")
print(f"Match: \t{args.match}")
print(f"Uri: \t{args.uri}")
print(f"Threads: {args.threads}")
print(f"Timeout: {args.timeout}\n")
logging.info("STARTING...")
def iterable_list(item_list):
ipv4_list = []
item_list = item_list.split(",")
for item in item_list:
try:
ip_range = IPNetwork(item)
ipv4_list = list(ip_range) + ipv4_list
except:
logging.error(str(item) + " is not valid ipv4 address or range")
sys.exit()
return ipv4_list, len(ipv4_list)
def distribute_addresses(ipv4list, threads, items_per_thread):
# create one dimension for each thread
ipv4_addrs = dict()
for i, ip in enumerate(ipv4list):
ipv4_addrs.setdefault(int(i / items_per_thread), []).append(str(ip))
return ipv4_addrs
def launch_thread(th_number, ipv4_addrs, args):
for addr, protocol in itertools.product(ipv4_addrs.get(th_number, []), PROTOCOLS):
logging.debug(f"[TH: {th_number}], addr: {addr}, protocol: {protocol}")
send_request(addr, protocol, args)
def send_request(ipaddr, protocol, args):
global sent_requests, matches
sent_requests = sent_requests + 1
progress_control()
target = f"{protocol}://{ipaddr}{args.uri}"
logging.debug(f"Trying {target}...")
try:
headers = {
"User-Agent": "Mozilla/5.0 (X11; Ubuntu; Linux x86_64; rv:66.0) Gecko/20100101 Firefox/66.0",
"Host": args.hostname,
}
response = requests.get(
target, headers=headers, verify=False, timeout=args.timeout, allow_redirects=False
)
if str(args.match) in str(response.content):
matches = matches + 1
resp_size = str(round(len(response.content) / 1024))
msg = f"\033[92m{protocol} request to {ipaddr} matchs ({resp_size}kb)\033[0m \n \
check it: \"curl -H 'Host: {args.hostname}' {target} -k\""
logging.info(f"{msg}")
except:
logging.debug(f"{target} not responds")
def progress_control():
global total_requests, sent_requests, matches
percent = sent_requests / (total_requests / 100);
sys.stdout.write(f"Progress: "+("%.2f" % percent)+"% \r")
sys.stdout.flush()
if sent_requests >= total_requests:
matches_str = str(matches) if matches else "ZERO"
logging.info(f"FINISHED WITH {matches_str} MATCHES \n")
os._exit(0)
def main(args):
global range_length, total_requests
try:
#create network object
ip_list, range_length = iterable_list(args.target_list)
total_requests = range_length * 2 # each address has 2 requests
#calculate addresses per thread
items_per_thread = math.ceil(range_length / args.threads)
# distribute addresses to threads
ipv4_addrs = distribute_addresses(ip_list, args.threads, items_per_thread)
#show details
print_banner(args)
# start threads
for i in range(args.threads):
_thread.start_new_thread(launch_thread, (i, ipv4_addrs, args))
except Exception as e:
logging.warning(f"Error: unable to start thread. {e}")
while True:
pass
if __name__ == "__main__":
parser = ArgumentParser(
add_help=True,
description="This tool helps you to find a website server ip in an ipv4 range or list.",
usage=SUPPRESS,
)
parser.add_argument("hostname", help="Ex: site.com")
parser.add_argument("target_list", help="List of ip addresses or ranges | Ex: 0.0.0.0/24,5.5.5.5,6.6.6.6")
parser.add_argument("match", help='Ex: "welcome to site.com"')
parser.add_argument("-u", "--uri", help="Ex: /en/index.aspx", default="/")
parser.add_argument("-t", "--threads", help="", type=int, default=10)
parser.add_argument("-T", "--timeout", help="", type=int, default=3)
parser.add_argument(
"-v", "--verbose", help="Verbose mode", dest="verbose", action="store_true"
)
args = parser.parse_args()
logging_level = logging.DEBUG if args.verbose else logging.INFO
logging.basicConfig(level=logging_level, format=LOGGING_FORMAT, datefmt='%H:%M:%S')
try:
main(args)
except KeyboardInterrupt:
print("\nStopped")
sys.exit()requirements.txt
urllib3==1.25.8
netaddr==0.8.0
requests==2.22.0
使用方法
①下载压缩包
②解压
③到文件根目录运行如下命令
pip3 install -r requirements.txt④输入如下命令开始爆破真实ip
python3 real_ip_discover.py "网址" IP地址范围 "<title网站标题" -t50
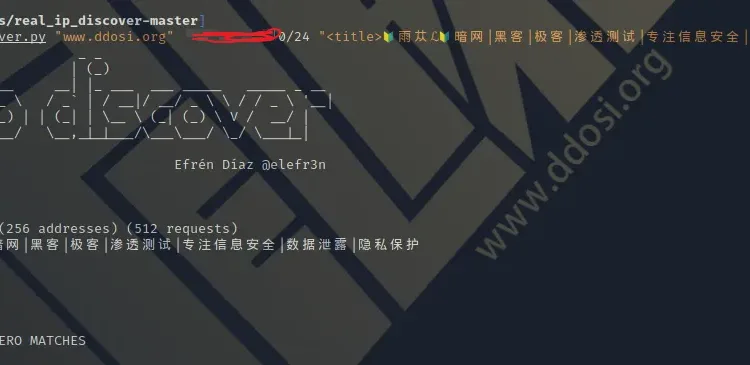
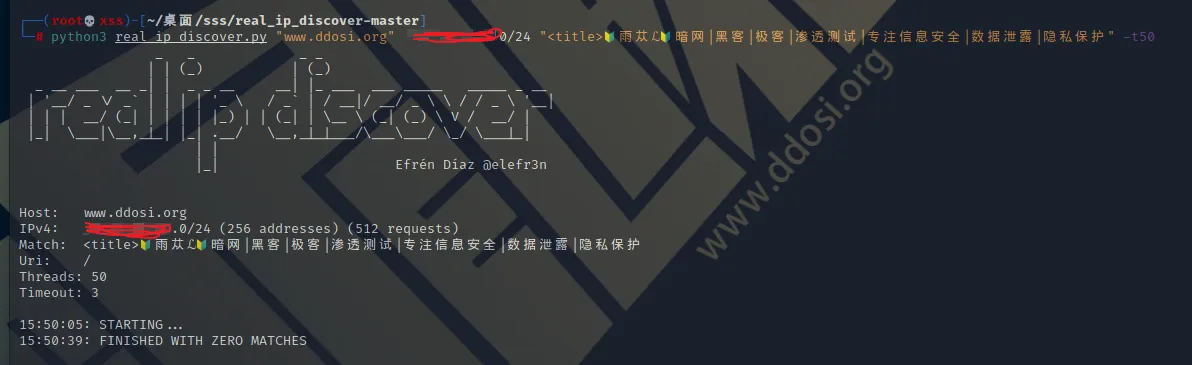
例如:
python3 real_ip_discover.py "www.ddosi.org" 47.155.218.0/24 "<title>?雨苁ℒ?暗网|黑客|极客|渗透测试|专注信息安全|数据泄露|隐私保护" -t50参数
参数位置:
hostname 例如: ddosi.org
target_list ip地址范围 | 例如: 0.0.0.0/24,5.5.5.5,6.6.6.6
match 例如: "?雨苁ℒ?暗网|黑客|极客|渗透测试|专注信息安全|数据泄露|隐私保护"
可选参数:
-h, --help 展示帮助信息并退出
-u URI, --uri URI 例如: /en/index.aspx
-t THREADS, --threads 线程
-T TIMEOUT, --timeout 超时
-v, --verbose 详细模式使用示例
python3 real_ip_discover.py "www.ddosi.org" 47.155.218.0/24 "<title>?雨苁ℒ?暗网|黑客|极客|渗透测试|专注信息安全|数据泄露|隐私保护" -t50
转载请注明出处及连接