
目录导航
Psudohash简介
psudohash 是一个用于编排暴力攻击的密码列表生成器。它模仿了人类常用的某些密码创建模式,例如用符号或数字替换单词的字母、使用字符大小写变体、在单词之前或之后添加常见的填充等等。它基于关键字且高度可定制。
使用示例
企业环境渗透
系统管理员和其他员工经常使用公司名称的变异版本来设置密码(例如 Am@z0n_2022)。这通常是网络设备(Wi-Fi 接入点、交换机、路由器等)、应用程序甚至域帐户的情况。使用最基本的选项,psudohash 可以根据常见的字符替换模式(可定制)、大小写变化、通常用作填充的字符串等生成一个包含一个或多个关键字的所有可能突变的词表。看看下面的例子:
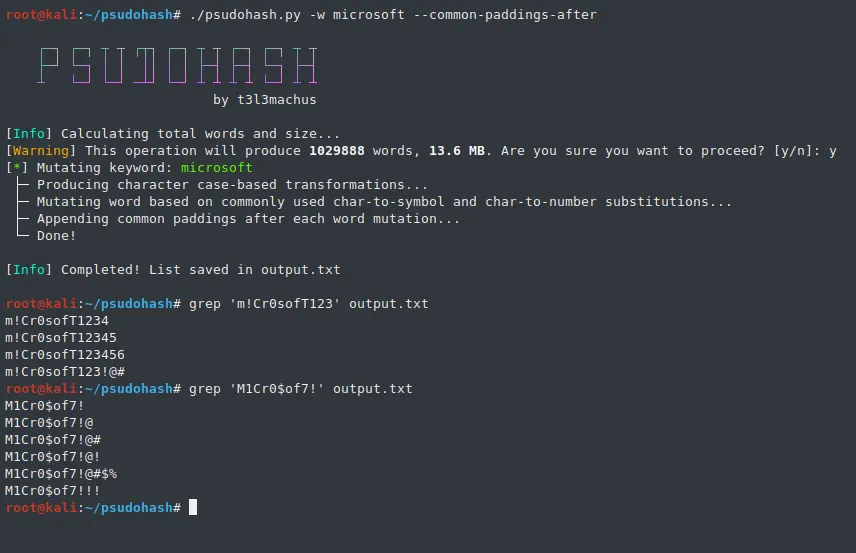
该脚本包括一个基本的字符替换模式。您可以通过编辑源代码并遵循以下数据结构逻辑(默认)来添加/修改字符替换模式:
transformations = [
{'a' : '@'},
{'b' : '8'},
{'e' : '3'},
{'g' : ['9', '6']},
{'i' : ['1', '!']},
{'o' : '0'},
{'s' : ['$', '5']},
{'t' : '7'}
]针对个人渗透
说到人,我认为我们都(或多或少)使用一个或多个对我们有意义的词的突变来设置密码,例如,我们的名字或妻子/孩子/宠物/乐队的名字,坚持我们的那一年出生在最后,或者可能是像“!@#”
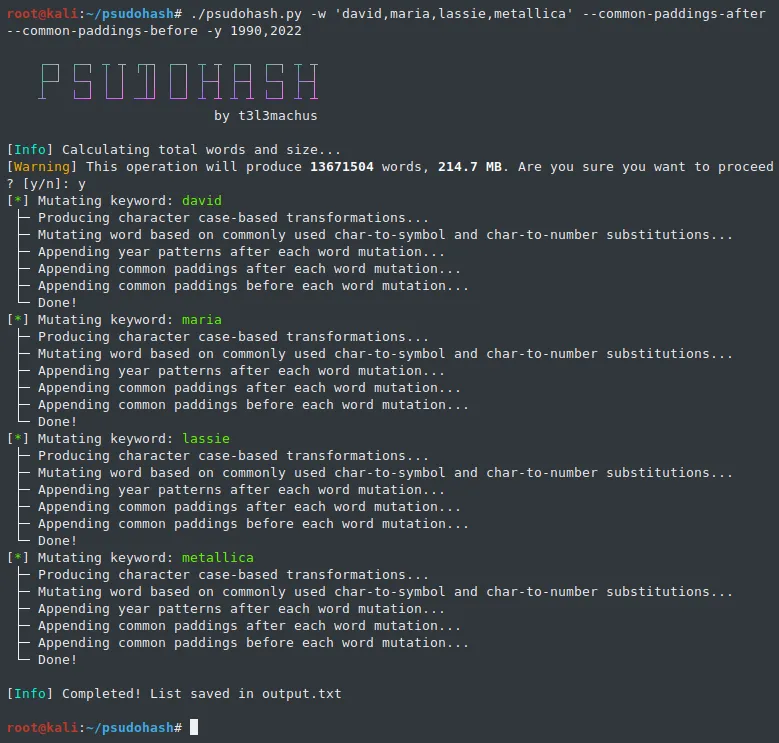
下载地址
直接保存为Psudohash.py即可
#!/bin/python3
#
# Created by Panagiotis Chartas (t3l3machus)
# https://github.com/t3l3machus
import argparse, sys, itertools
# Colors
MAIN = '\033[38;5;50m'
LOGO = '\033[38;5;41m'
LOGO2 = '\033[38;5;42m'
GREEN = '\033[38;5;82m'
ORANGE = '\033[0;38;5;214m'
PRPL = '\033[0;38;5;26m'
PRPL2 = '\033[0;38;5;25m'
RED = '\033[1;31m'
END = '\033[0m'
BOLD = '\033[1m'
# -------------- Arguments & Usage -------------- #
parser = argparse.ArgumentParser(
formatter_class=argparse.RawTextHelpFormatter,
epilog='''
Usage examples:
Basic:
python3 psudohash.py -w <keywords> -cpa
Thorough:
python3 psudohash.py -w <keywords> -cpa -cpb -an 3 -y 1990-2022
'''
)
parser.add_argument("-w", "--words", action="store", help = "Comma seperated keywords to mutate", required = True)
parser.add_argument("-an", "--append-numbering", action="store", help = "Append numbering range at the end of each word mutation (before appending year or common paddings).\nThe LEVEL value represents the minimum number of digits. LEVEL must be >= 1. \nSet to 1 will append range: 1,2,3..100\nSet to 2 will append range: 01,02,03..100 + previous\nSet to 3 will append range: 001,002,003..100 + previous.\n\n", type = int, metavar='LEVEL')
parser.add_argument("-nl", "--numbering-limit", action="store", help = "Change max numbering limit value of option -an. Default is 50. Must be used with -an.", type = int, metavar='LIMIT')
parser.add_argument("-y", "--years", action="store", help = "Singe OR comma seperated OR range of years to be appended to each word mutation (Example: 2022 OR 1990,2017,2022 OR 1990-2000)")
parser.add_argument("-ap", "--append-padding", action="store", help = "Add comma seperated values to common paddings (must be used with -cpb OR -cpa)", metavar='VALUES')
parser.add_argument("-cpb", "--common-paddings-before", action="store_true", help = "Append common paddings before each mutated word")
parser.add_argument("-cpa", "--common-paddings-after", action="store_true", help = "Append common paddings after each mutated word")
parser.add_argument("-cpo", "--custom-paddings-only", action="store_true", help = "Use only user provided paddings for word mutations (must be used with -ap AND (-cpb OR -cpa))")
parser.add_argument("-o", "--output", action="store", help = "Output filename (default: output.txt)", metavar='FILENAME')
parser.add_argument("-q", "--quiet", action="store_true", help = "Do not print the banner on startup")
args = parser.parse_args()
def exit_with_msg(msg):
parser.print_help()
print(f'\n[{RED}Debug{END}] {msg}\n')
sys.exit(1)
def unique(l):
unique_list = []
for i in l:
if i not in unique_list:
unique_list.append(i)
return unique_list
# Append numbering
if args.numbering_limit and not args.append_numbering:
exit_with_msg('Option -nl must be used with -an.')
if args.append_numbering:
if args.append_numbering <= 0:
exit_with_msg('Numbering level must be > 0.')
_max = args.numbering_limit + 1 if args.numbering_limit and isinstance(args.numbering_limit, int) else 51
# Create years list
if args.years:
years = []
if args.years.count(',') == 0 and args.years.count('-') == 0 and args.years.isdecimal() and int(args.years) >= 1000 and int(args.years) <= 3200:
years.append(str(args.years))
elif args.years.count(',') > 0:
for year in args.years.split(','):
if year.strip() != '' and year.isdecimal() and int(year) >= 1000 and int(year) <= 3200:
years.append(year)
else:
exit_with_msg('Illegal year(s) input. Acceptable years range: 1000 - 3200.')
elif args.years.count('-') == 1:
years_range = args.years.split('-')
start_year = years_range[0]
end_year = years_range[1]
if (start_year.isdecimal() and int(start_year) < int(end_year) and int(start_year) >= 1000) and (end_year.isdecimal() and int(end_year) <= 3200):
for y in range(int(years_range[0]), int(years_range[1])+1):
years.append(str(y))
else:
exit_with_msg('Illegal year(s) input. Acceptable years range: 1000 - 3200.')
else:
exit_with_msg('Illegal year(s) input. Acceptable years range: 1000 - 3200.')
def banner():
padding = ' '
P = [[' ', '┌', '─', '┐'], [' ', '├','─','┘'], [' ', '┴',' ',' ']]
S = [[' ', '┌','─','┐'], [' ', '└','─','┐'], [' ', '└','─','┘']]
U = [[' ', '┬',' ','┬'], [' ', '│',' ','│'], [' ', '└','─','┘']]
D = [[' ', '┌','┬','┐'], [' ', ' ','│','│'], [' ', '─','┴','┘']]
O = [[' ', '┌','─','┐'], [' ', '│',' ','│'], [' ', '└','─','┘']]
H = [[' ', '┐', ' ', '┌'], [' ', '├','╫','┤'], [' ', '┘',' ','└']]
A = [[' ', '┌','─','┐'], [' ', '├','─','┤'], [' ', '┴',' ','┴']]
S = [[' ', '┌','─','┐'], [' ', '└','─','┐'], [' ', '└','─','┘']]
H = [[' ', '┬',' ','┬'], [' ', '├','─','┤'], [' ', '┴',' ','┴']]
banner = [P,S,U,D,O,H,A,S,H]
final = []
print('\r')
init_color = 37
txt_color = init_color
cl = 0
for charset in range(0, 3):
for pos in range(0, len(banner)):
for i in range(0, len(banner[pos][charset])):
clr = f'\033[38;5;{txt_color}m'
char = f'{clr}{banner[pos][charset][i]}'
final.append(char)
cl += 1
txt_color = txt_color + 36 if cl <= 3 else txt_color
cl = 0
txt_color = init_color
init_color += 31
if charset < 2: final.append('\n ')
print(f" {''.join(final)}")
print(f'{END}{padding} by t3l3machus\n')
# ----------------( Base Settings )---------------- #
mutations_cage = []
basic_mutations = []
outfile = args.output if args.output else 'output.txt'
trans_keys = []
transformations = [
{'a' : '@'},
{'b' : '8'},
{'e' : '3'},
{'g' : ['9', '6']},
{'i' : ['1', '!']},
{'o' : '0'},
{'s' : ['$', '5']},
{'t' : '7'}
]
for t in transformations:
for key in t.keys():
trans_keys.append(key)
# Paddings
if (args.custom_paddings_only or args.append_padding) and not (args.common_paddings_before or args.common_paddings_after):
exit_with_msg('Options -ap and -cpo must be used with -cpa or -cpb.')
elif (args.common_paddings_before or args.common_paddings_after) and not args.custom_paddings_only:
common_paddings = [
'!', '@', '#', '$', '%', '^', '&', '*', ',', '.', '?', '-' \
'123', '234', '345', '456', '567', '678', '789', '890',\
'!@', '@#', '#$', '$%', '%^', '^&', '&*', '*(', '()', \
'!@#', '@#$', '#$%', '$%^', '%^&', '^&*', '&*(', '*()', ')_+',\
'1!1', '2@2', '3#3', '4$4', '5%5', '6^6', '7&7', '8*8', '9(9', '0)0',\
'@2@', '#3#', '$4$', '%5%', '^6^', '&7&', '*8*', '(9(', \
'!@!', '@#@', '!@#$%', '1234', '12345', '123456', '123!@#', \
'!!!', '@@@', '###', '$$$', '%%%', '^^^', '&&&', '***', '(((', ')))', '---', '+++'
]
elif (args.common_paddings_before or args.common_paddings_after) and (args.custom_paddings_only and args.append_padding):
common_paddings = []
elif not (args.common_paddings_before or args.common_paddings_after):
common_paddings = []
else:
exit_with_msg('\nIllegal padding settings.\n')
if args.append_padding:
for val in args.append_padding.split(','):
if val.strip() != '' and val not in common_paddings:
common_paddings.append(val)
if (args.common_paddings_before or args.common_paddings_after):
common_paddings = unique(common_paddings)
# ----------------( Functions )---------------- #
def evalTransformations(w):
trans_chars = []
total = 1
c = 0
w = list(w)
for char in w:
for t in transformations:
if char in t.keys():
trans_chars.append(c)
if isinstance(t[char], list):
total *= 3
else:
total *= 2
c += 1
return [trans_chars, total]
def mutate(tc, word):
global trans_keys, mutations_cage, basic_mutations
i = trans_keys.index(word[tc].lower())
trans = transformations[i][word[tc].lower()]
limit = len(trans) * len(mutations_cage)
c = 0
for m in mutations_cage:
w = list(m)
if isinstance(trans, list):
for tt in trans:
w[tc] = tt
transformed = ''.join(w)
mutations_cage.append(transformed)
c += 1
else:
w[tc] = trans
transformed = ''.join(w)
mutations_cage.append(transformed)
c += 1
if limit == c: break
return mutations_cage
def mutations_handler(kword, trans_chars, total):
global mutations_cage, basic_mutations
container = []
for word in basic_mutations:
mutations_cage = [word.strip()]
for tc in trans_chars:
results = mutate(tc, kword)
container.append(results)
for m_set in container:
for m in m_set:
basic_mutations.append(m)
basic_mutations = unique(basic_mutations)
with open(outfile, 'a') as wordlist:
for m in basic_mutations:
wordlist.write(m + '\n')
def mutateCase(word):
trans = list(map(''.join, itertools.product(*zip(word.upper(), word.lower()))))
return trans
def caseMutationsHandler(word, mutability):
global basic_mutations
case_mutations = mutateCase(word)
for m in case_mutations:
basic_mutations.append(m)
if not mutability:
basic_mutations = unique(basic_mutations)
with open(outfile, 'a') as wordlist:
for m in basic_mutations:
wordlist.write(m + '\n')
def append_numbering():
global _max
first_cycle = True
previous_list = []
lvl = args.append_numbering
with open(outfile, 'a') as wordlist:
for word in basic_mutations:
for i in range(1, lvl+1):
for k in range(1, _max):
if first_cycle:
wordlist.write(f'{word}{str(k).zfill(i)}\n')
wordlist.write(f'{word}_{str(k).zfill(i)}\n')
previous_list.append(f'{word}{str(k).zfill(i)}')
else:
if previous_list[k - 1] != f'{word}{str(k).zfill(i)}':
wordlist.write(f'{word}{str(k).zfill(i)}\n')
wordlist.write(f'{word}_{str(k).zfill(i)}\n')
previous_list[k - 1] = f'{word}{str(k).zfill(i)}'
first_cycle = False
del previous_list
def mutate_years():
current_mutations = basic_mutations.copy()
with open(outfile, 'a') as wordlist:
for word in current_mutations:
for y in years:
wordlist.write(f'{word}{y}\n')
wordlist.write(f'{word}_{y}\n')
wordlist.write(f'{word}{y[2:]}\n')
basic_mutations.append(f'{word}{y}')
basic_mutations.append(f'{word}_{y}')
basic_mutations.append(f'{word}{y[2:]}')
del current_mutations
def check_underscore(word, pos):
if word[pos] == '_':
return True
else:
return False
def append_paddings_before():
current_mutations = basic_mutations.copy()
with open(outfile, 'a') as wordlist:
for word in current_mutations:
for val in common_paddings:
wordlist.write(f'{val}{word}\n')
if not check_underscore(val, -1):
wordlist.write(f'{val}_{word}\n')
del current_mutations
def append_paddings_after():
current_mutations = basic_mutations.copy()
with open(outfile, 'a') as wordlist:
for word in current_mutations:
for val in common_paddings:
wordlist.write(f'{word}{val}\n')
if not check_underscore(val, 0):
wordlist.write(f'{word}_{val}\n')
del current_mutations
def calculate_output(keyw):
global trans_keys
c = 0
total = 1
basic_total = 1
basic_size = 0
size = 0
numbering_count = 0
numbering_size = 0
# Basic mutations calc
for char in keyw:
if char in trans_keys:
i = trans_keys.index(keyw[c].lower())
trans = transformations[i][keyw[c].lower()]
basic_total *= (len(trans) + 2)
else:
basic_total = basic_total * 2 if char.isalpha() else basic_total
c += 1
total = basic_total
basic_size = total * (len(keyw) + 1)
size = basic_size
# Words numbering mutations calc
if args.append_numbering:
global _max
word_len = len(keyw) + 1
first_cycle = True
previous_list = []
lvl = args.append_numbering
for w in range(0, total):
for i in range(1, lvl+1):
for k in range(1, _max):
n = str(k).zfill(i)
if first_cycle:
numbering_count += 2
numbering_size += (word_len * 2) + (len(n) * 2) + 1
previous_list.append(f'{w}{n}')
else:
if previous_list[k - 1] != f'{w}{n}':
numbering_size += (word_len * 2) + (len(n) * 2) + 1
numbering_count += 2
previous_list[k - 1] = f'{w}{n}'
first_cycle = False
del previous_list
# Adding years mutations calc
if args.years:
patterns = 3
year_chars = 4
_year = 5
year_short = 2
yrs = len(years)
size += (basic_size * patterns * yrs) + (basic_total * year_chars * yrs) + (basic_total * _year * yrs) + (basic_total * year_short * yrs)
total += total * len(years) * 3
basic_total = total
basic_size = size
# Common paddings mutations calc
patterns = 2
if args.common_paddings_after or args.common_paddings_before:
paddings_len = len(common_paddings)
pads_wlen_sum = sum([basic_total*len(w) for w in common_paddings])
_pads_wlen_sum = sum([basic_total*(len(w)+1) for w in common_paddings])
if args.common_paddings_after and args.common_paddings_before:
size += ((basic_size * patterns * paddings_len) + pads_wlen_sum + _pads_wlen_sum) * 2
total += (total * len(common_paddings) * 2) * 2
elif args.common_paddings_after or args.common_paddings_before:
size += (basic_size * patterns * paddings_len) + pads_wlen_sum + _pads_wlen_sum
total += total * len(common_paddings) * 2
return [total + numbering_count, size + numbering_size]
def check_mutability(word):
global trans_keys
m = 0
for char in word:
if char in trans_keys:
m += 1
return m
def chill():
pass
def main():
banner() if not args.quiet else chill()
global basic_mutations, mutations_cage
keywords = []
for w in args.words.split(','):
if w.strip().isdecimal():
exit_with_msg('Unable to mutate digit-only keywords.')
elif w.strip() not in [None, '']:
keywords.append(w.strip())
# Calculate total words and size of output
total_size = [0, 0]
for keyw in keywords:
count_size = calculate_output(keyw.strip().lower())
total_size[0] += count_size[0]
total_size[1] += count_size[1]
size = round(((total_size[1]/1000)/1000), 1) if total_size[1] > 100000 else total_size[1]
prefix = 'bytes' if total_size[1] <= 100000 else 'MB'
fsize = f'{size} {prefix}'
print(f'[{MAIN}Info{END}] Calculating total words and size...')
concent = input(f'[{ORANGE}Warning{END}] This operation will produce {BOLD}{total_size[0]}{END} words, {BOLD}{fsize}{END}. Are you sure you want to proceed? [y/n]: ')
if concent.lower() not in ['y', 'yes']:
sys.exit(f'\n[{RED}X{END}] Aborting.')
else:
open(outfile, "w").close()
for word in keywords:
print(f'[{GREEN}*{END}] Mutating keyword: {GREEN}{word}{END} ')
mutability = check_mutability(word.lower())
# Produce case mutations
print(f' ├─ Producing character case-based transformations... ')
caseMutationsHandler(word.lower(), mutability)
if mutability:
# Produce char substitution mutations
print(f' ├─ Mutating word based on commonly used char-to-symbol and char-to-number substitutions... ')
trans = evalTransformations(word.lower())
mutations_handler(word, trans[0], trans[1])
else:
print(f' ├─ {ORANGE}No character substitution instructions match this word.{END}')
# Append numbering
if args.append_numbering:
print(f' ├─ Appending numbering to each word mutation... ')
append_numbering()
# Handle years
if args.years:
print(f' ├─ Appending year patterns after each word mutation... ')
mutate_years()
# Append common paddings
if args.common_paddings_after or args.custom_paddings_only:
print(f' ├─ Appending common paddings after each word mutation... ')
append_paddings_after()
if args.common_paddings_before:
print(f' ├─ Appending common paddings before each word mutation... ')
append_paddings_before()
basic_mutations = []
mutations_cage = []
print(f' └─ Done!')
print(f'\n[{MAIN}Info{END}] Completed! List saved in {outfile}\n')
if __name__ == '__main__':
main()安装方法
git clone https://github.com/t3l3machus/psudohash
cd ./psudohash
chmod +x psudohash.py
python3 psudohash.py使用方法
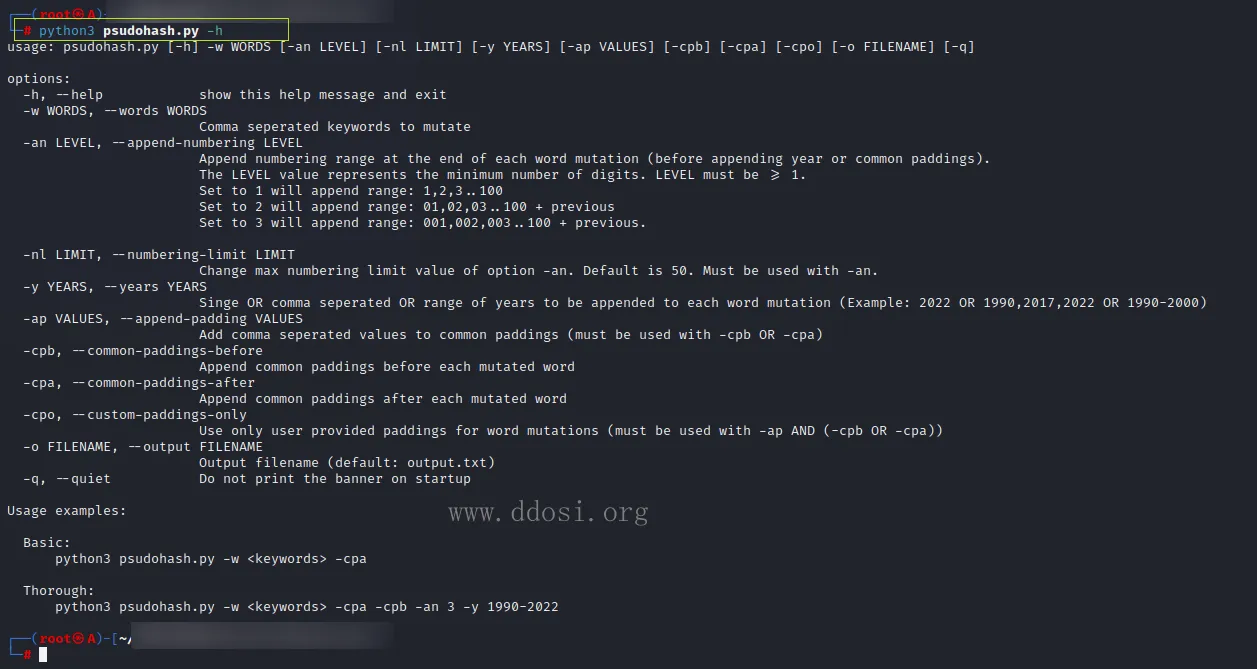
用法: psudohash.py [-h] -w WORDS [-an LEVEL] [-nl LIMIT] [-y YEARS] [-ap VALUES] [-cpb] [-cpa] [-cpo] [-o FILENAME] [-q]
选项:
-h, --help 显示此帮助消息并退出
-w WORDS, --words WORDS
要变异的关键字-逗号分隔
-an LEVEL, --append-numbering LEVEL
在每个单词变异的末尾追加编号范围(在追加年份或公共填充之前)。
LEVEL值表示最小位数。LEVEL必须为>= 1。
设置为1将附加范围:1,2,3..100
设置为2将附加范围:01,02,03..100+之前
设置为3将附加范围:001,002,003..100+之前。
-nl LIMIT, --numbering-limit LIMIT
更改选项-an的最大编号限制值。默认是50。必须与-an连用。
-y YEARS, --years YEARS
每一个单词变异后,用逗号分隔的年份或范围(例如:2022 OR 1990,2017,2022 OR 1990-2000)
-ap VALUES, --append-padding VALUES
在普通填充中添加逗号分隔的值(必须与-cpb或-cpa一起使用)
-cpb, --common-paddings-before
在每个变异的单词前添加普通填充
-cpa, --common-paddings-after
在每个变异的单词后添加普通填充
-cpo, --custom-paddings-only
仅对突变使用用户提供的单词填充符(必须与-ap AND (-cpb OR -cpa)一起使用)
-o FILENAME, --output FILENAME
输出文件名(默认值:Output .txt)
-q, --quiet 启动时不打印横幅
用法示例:
基本:
python3 psudohash.py -w <keywords> -cpa
彻底的:
python3 psudohash.py -w <keywords> -cpa -cpb -an 3 -y 1990-2022
使用技巧
- 由于工具实现的突变模式,组合选项
--years和--append-numbering用一个--numbering-limit≥任何年份输入的后两位数字很可能会产生重复的单词. - 如果您在源代码中添加自定义填充值或修改预定义的公共填充值,并结合多个可选参数,则出现重复单词的可能性很小。psudohash 包括单词过滤控件,但为了速度,这些是有限的。
测试截图
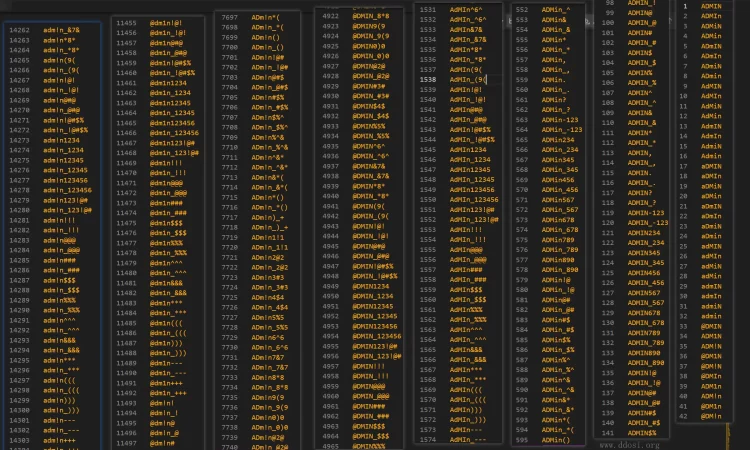
我们单纯使用admin来进行生成测试,命令如下:
python3 psudohash.py -w 'admin' -cpa共计生成了14304个字典列表
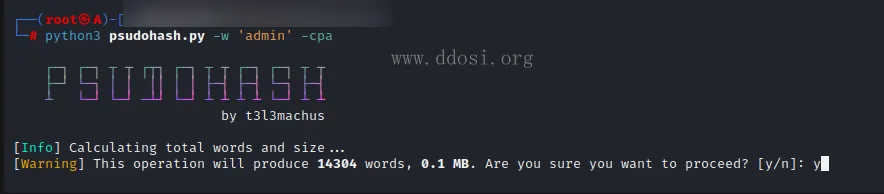
让我们看看有哪些组合:
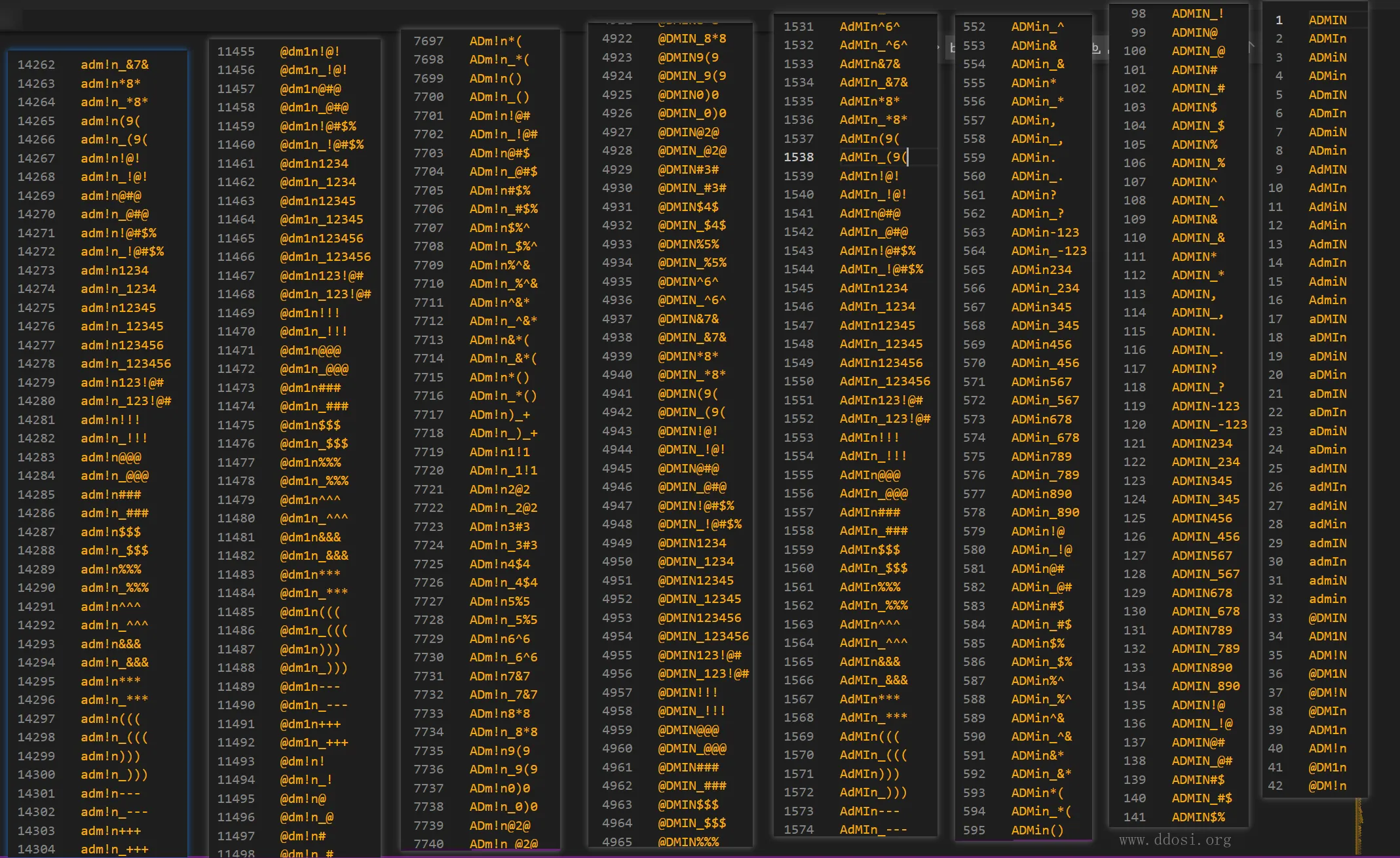
有点多了,可能缺点就是太全了
项目地址:
https://github.com/t3l3machus/psudohash
转载请注明出处及链接